Bulk RDBMS Upserts with Spring

Upsert is a fairly common terminology in databases, meaning Update if the record exists or Insert the new record. Upserts make more sense in case of simple object save requests with new information.
Why Bulk?
If we talk about any data sync, data migration or bulk data update jobs, we are bound to have a bulk upsert scenario to update whatever we have in the database and insert all the new rows.
Solutions
We will be discussing about the solutions present in the Spring Boot environment and inferences we make out of them.
For the testing, I will be using MS SQL Server as the database and will be limited to it’s functionality but the concepts are fairly generalisable.
#1 Standard saveAll() Solution using Spring JPA
Consider we have a price table with a composite unique key/constraints having like with structure:
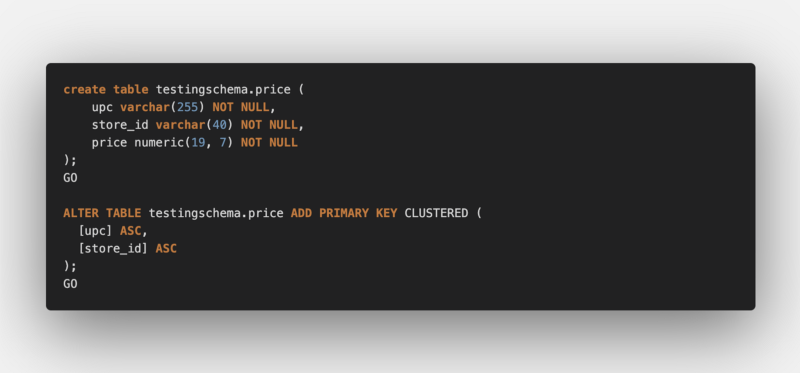
Then, our entity’s composite primary key and entity classes would look like:
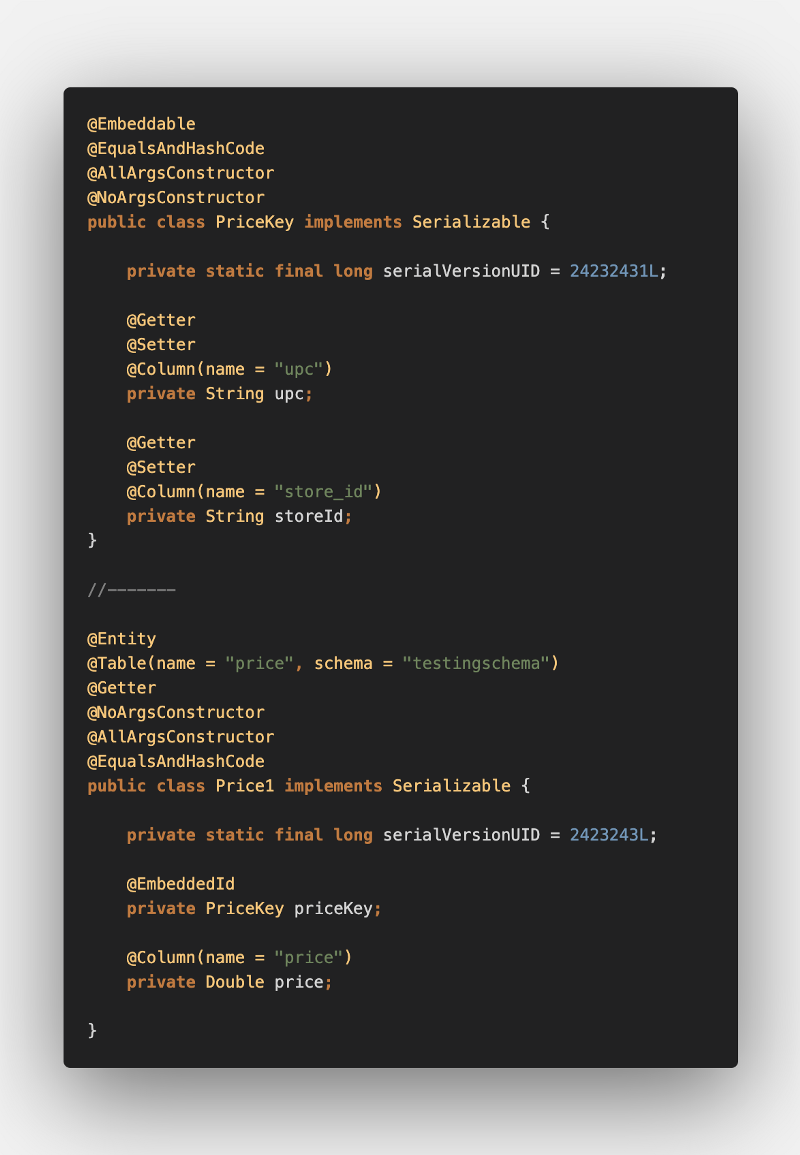
Assume we are consuming a stream of record batches to upsert. To mock this, we have a supplier to generate a random Price1 object batches of size 1000. The ingestion code:
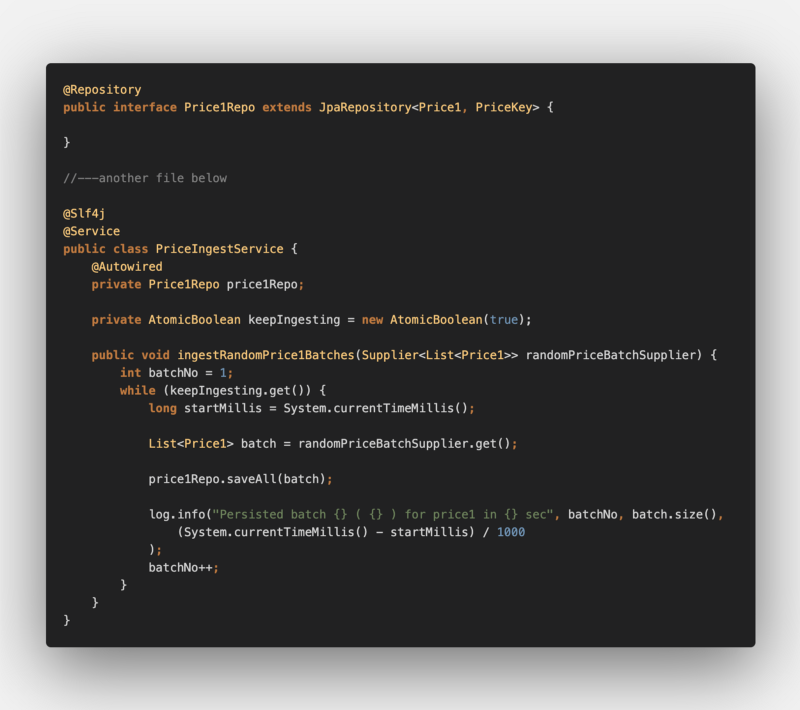
Let’s see the results:
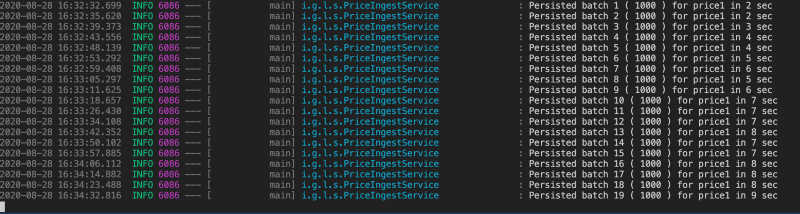
Now, on looking closely the time taken to persist each batch increases as the table get filled up! What is this?
The culprit is the the method .save() of SimpleJPARepository class:

Since, the save performs both the insert and update operation, it has to check whether an entity is “new” or not. For which, it has to either check in the persistence context or query the database, which will get complex in time as the table get filled up.
#2 Optimisations for Bulk save
Our bottleneck in the previous approach was continuous reads from the DB for a primary key combination to check whether to perform .persist() / insert or .merge() / update.
To avoid additional querying on the table for .isNew() we could have another auto generated unique field (row) which is independent of the business logic. So that, every new object will have a unique id and will always do .persist() for them.
Let’s do the modifications on a completely new table (keeping the business columns as they are), with an additional auto-incremented “identity” column :
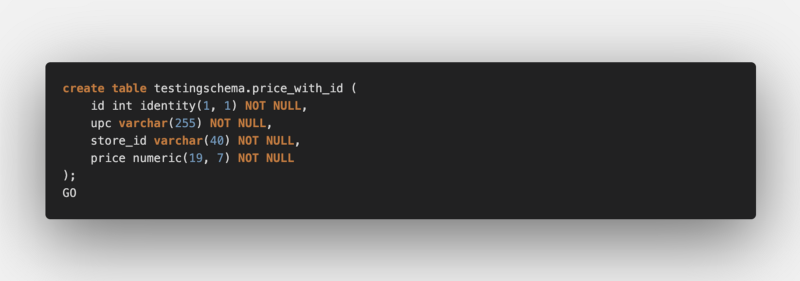
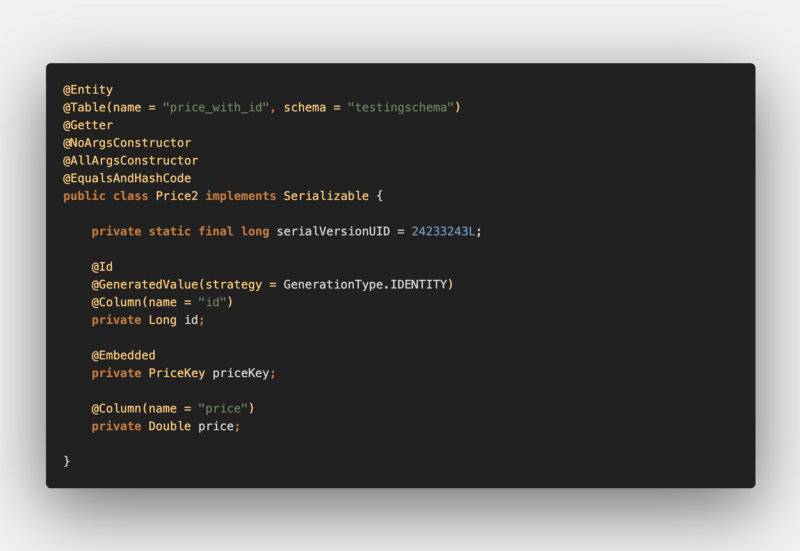
Here is our entity:
Testing out similar ingestion code will yield the result like below:
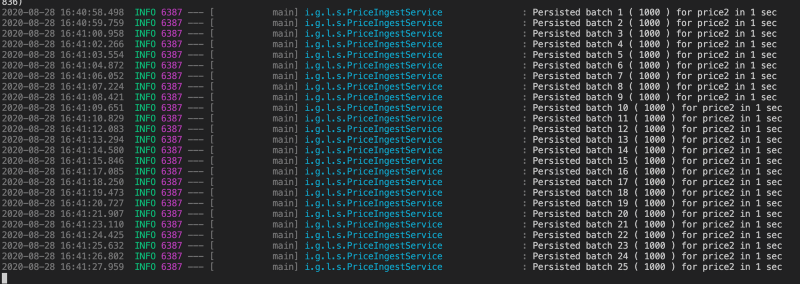
Hooray, Constant time and faster inserts! But wait,
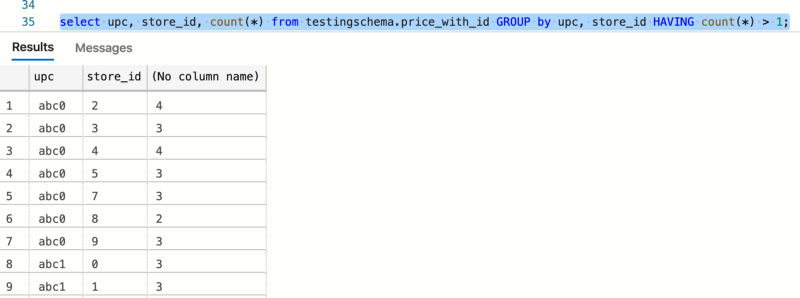
There are now duplicate rows with upc, store_id combinations

Which is understandable, as we are doing no updates.
#3 Plain inserts then merge
The above 2 experiments have encouraged us to keep the insert model for faster inserts and somehow merge (do updates) later.
To achieve this, we can have a “stage” table having a unique auto-generated id for inserts, separate from our target main table. And a pos-ingestion job for merging the records after de-duplicating.

Plain inserts can go as the done above, we will now try to write a “merge” step. This step can very well be database stored procedure due to following reasons:
- To avoid movement of data and process the bulk data where it resides.
- Database specific optimisations are built-in.
Following is an example naive implementation of a merge stored procedure for MS SQL, similar merge query features are present most of the mainstream databases.
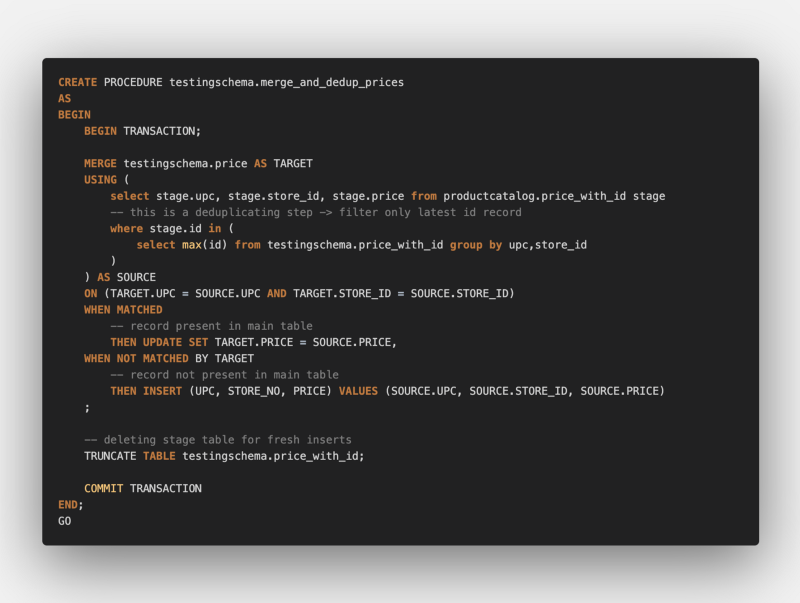
Executing this took less than a second!

Important Notes: The above stored procedure implementation is a very naive approach just to demonstrate and misses on a lot of the aspects to be taken care of in a production environment, like:
- Over utilising transaction log size due to huge data in the merge statement, **batch-wise merging with id range**could be implemented here.
- Monitoring and logging procedure failures, a TRY-CATCH based procedure with logging failures in a procedure-audit logging table could be used.
- A successfully merged batch-range delete instead of truncating the stage table.
#Extra: Further Improving batch inserts
If we try to log the hibernate generated SQL statements for our .saveAll() operation, we will get something like this:

Here, we are firing single insert statements with values to insert, each going over the network.
There are some improvements that can be done here:
- Batch the queries and fire in call to the database over network.
- Rewrite the single queries into a form of single multi-row query.
For first, we can make use of hibernate properties:
spring.jpa.properties.hibernate.jdbc.batch_size=1000
spring.jpa.properties.hibernate.order_inserts=true
For second, there are bulk (multi-row) insert query options available in most of the mainstream database solutions (Postgres, MySQL, Oracle). With syntax like:
insert into myschema.my_table (col1, col2, col3)
values
(val11, val12, val13),
(val21, val22, val23),
....
(valn1, valn2, valn3);
While, Postgres and MySQL do support this features with the help of JDBC flag: reWriteBatchedInserts=true
But unfortunately, according to this resource, ms-sql JDBC driver does not support the multi-row rewrite of the queries. So, if we want to do this, we would have to write the insert queries manually.
Manual insert query creation could look like:
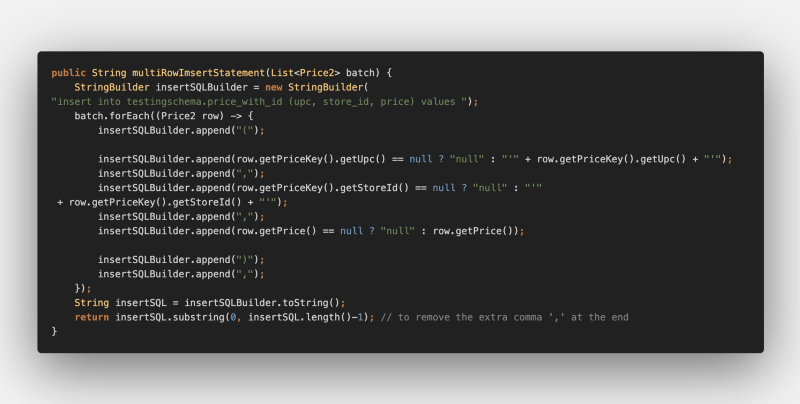
The ingestion code would use entityManager.createNativeQuery() method:
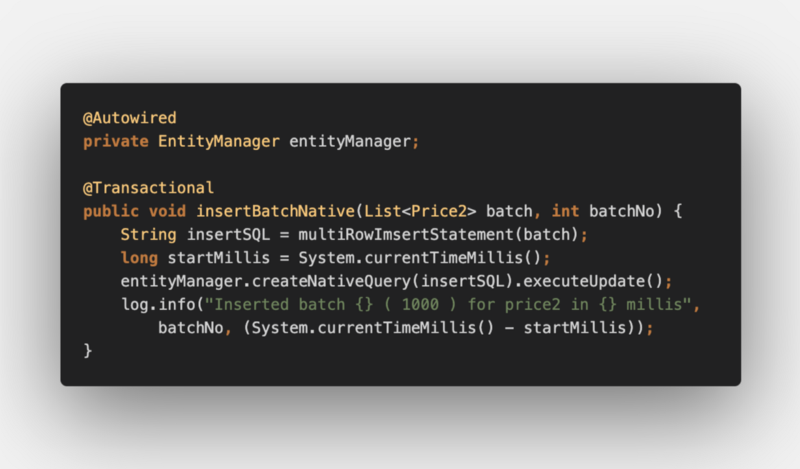
Let’s test it out:
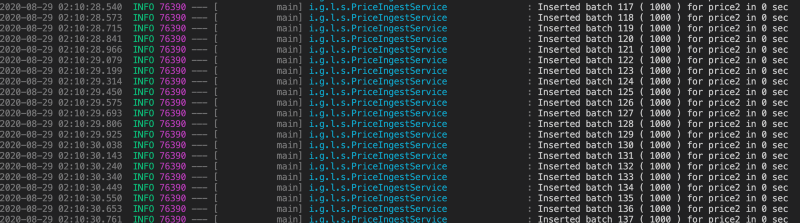
Wow!! Those batches of 1000 records took less than a second, let’s look at the milli seconds now:
Conclusion
We can safely infer from our above experiments that:
- Achieving bulk Upserts are really complicated in relational databases.
- Spring JPA and Hibernate provided out-of-the-box save methods won’t scale for huge loads.
- A decoupled (from business columns/fields) independent primary key will help improve the insert performance of the inserts, but will eventually insert duplicate records.
- Separating insert-only and read (actual) table can be used to improve ingestion performance.
- A post insert, merge strategy can be used for de-duplicating inserted records. Stored procedures work well in this scenario.
- Native SQL queries will give the most performant result, use solutions which are as close to the database as possible where performance is critical.
Testing Environment
- Macbook Pro 2016 model 15" with 16 GB RAM.
- Application uses Java 1.8 with Spring Boot 2.3.3.
- MS SQL server 2017 database in a Docker container.
Thanks for Reading :)